
Description
Aggregates or allocates a Block's data depending on the Dimensions given.
Returns a Block (Metric or Property) with different Dimensions. Pigment’s BY modifier can be used to both aggregate or allocate data depending on the relationship between the Dimensions used in the formula.
Syntax
Syntax is similar when using for allocation or aggregation, the difference is when defining the method.
source_blockrBY allocation_method: mapping attribute 1, imapping_attribute_2]]
or
source_blockrBY aggregation_method: mapping attribute 1, imapping_attribute_2]]
Source_blockuBY allocation method: mapping attribute 1, mapping attribute 2]
-
Source_blockis the Metric or List Property that contains the values to be aggregated or allocated -
allocation methodis where you define the way that values are distributed, this is an optional field. If it is not defined, values will be distributed by the CONSTANT method -
aggregation methodis where you define the way that values are aggregated, this is an optional field. If it is not defined, values will be aggregated using the SUM method. -
mapping_attribute_1is a List Property or Metric that defines the relationship between the Dimensions in the Source_block and the Dimensions in the target Metric. The mapping attribute must have a Dimension data type. You must have one mapping attribute per use of the BY modifier. -
mapping_attribute_2is optional. This can be used when aggregating or allocating across multiple Dimensions.
Return type
Depends on aggregation/allocation method. See below under each method for information.
Table of Contents
What is a mapping attribute?
A mapping attribute is used to define a relationship between two Lists. It can either be a Property on one of the Lists or a Metric using one of the Lists. The critical factor is that the Property or Metric has to have a Dimension data type.
| For example, if you have Country and Region Dimensions, you could use a mapping attribute to define how countries roll up to regions. In order to do this, you must create a Property or Metric that is set to the Dimension data type. Here you can see an example from a Country List. Because there are multiple countries within each region, you would set up the mapping property on the Country List. | 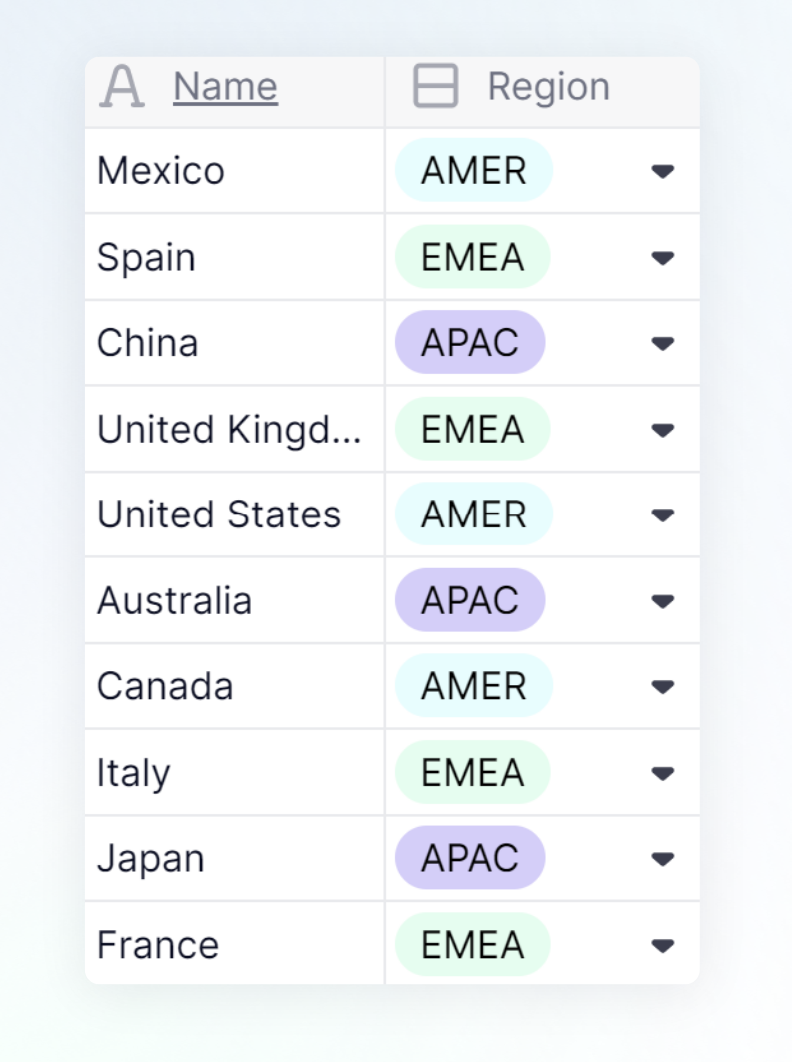
|
How do you set up allocation vs aggregation using BY?
The determining factor on whether data is allocated or aggregated when using the BY modifier is the relationship established in the mapping attribute. One relationship type is called One-to-Many (displayed as 1->N). This is where you have the value of one item that you want allocated across multiple items. The other relationship type is Many-to-One (displayed as N ->1). In this relationship, you have many items that are aggregated into one item.
One-to-Many
One-to-Many relationships are established when one item has a connection to many items in the other list. For example, one region, Europe, Middle East, Africa, (EMEA), has a relationship to many items in the country list, France, Spain, United Kingdom and Italy. If my source data is at the region level and I want to display it at the country level, that would be the One-to-Many relationship. This is because each region’s data would be distributed to many countries. In this example, the BY modifier would use an Allocation method.
Many-to-One
Many-to-One relationships are defined by multiple items being aggregated into one item. Let’s use the same example as above, where we have multiple countries rolling up to one region. If my source data is at the Country level and I want to display it at the Region level, this would be a Many-to-One relationship. In this example, the BY Modifier would use the Aggregation method. It would take the values from France, Spain, United Kingdom and Italy and aggregate them into the EMEA region.
The BY modifier will either allocate or aggregate based upon how we are trying to transform the data. If your source data is at the Country level and your formula is at the Region level, the BY modifier will aggregate those values. If your source data at the Region level and you want to calculate it at the country level, it will allocate the values. The default behavior for allocation is CONSTANT and the default behavior for aggregation is SUM. There are other methods below that you can use as long as you define them in the syntax.
 To learn more about using the BY Modifier, visit our Academy course on Formula Writing.
To learn more about using the BY Modifier, visit our Academy course on Formula Writing.
Allocation Methods
Constant
This method takes the value from the source Metric or Property and applies it to every Item within the replacement Dimensions. This is the default behavior if no allocation method is defined.
Source_blockeBY Constant: mapping attribute ]
Supported Data Types - All Types
Return Data Type - same as Input
Split
This method takes the value from the source Metric or Property and distributes it evenly across the Items within the replacement Dimensions.
Source_blocktBY split: mapping attribute ]
Supported Data Types - Number, Integer
Return Data Type - Number
Aggregation Methods
SUM
This method returns the sum of the source values from the aggregated Dimension. This is the default behavior when using BY.
Source_blockrBY: mapping attribute ]
Source_blocknBY SUM: mapping attribute ]
Supported Data Types - Number, Integer
Return Data Type - same as Input
AVG
This method returns the average of the source values from aggregated Dimension.
Source_blocktBY AVG: mapping attribute ]
Supported Data Types - Number, Integer
Return Data Type - Number
MIN
This method returns the minimum value of the source values from aggregated Dimension.
Source_blocksBY MIN: mapping attribute ]
Supported Data Types - Number, Integer, Date
Return Data Type - same as Input
MAX
This method returns the maximum value of the source values from aggregated Dimension.
Source_blockrBY MAX: mapping attribute ]
Supported Data Types - Number, Integer, Date
Return Data Type - same as Input
FIRSTNONBLANK
This method returns the first non blank value of the aggregated Dimension.
Source_block#BY FIRSTNONBLANK: mapping attribute ]
Supported Data Types - All Types
Return Data Type - same as Input
FIRSTNONZERO
This method returns the first non zero value of the aggregated Dimension.
Source_blocklBY FIRSTNONZERO: mapping attribute ]
Supported Data Types - Number, Integer
Return Data Type - same as Input
FIRST
This method returns the first value of the aggregated Dimension.
Source_blocknBY FIRST: mapping attribute ]
Supported Data Types - All Types
Return Data Type - same as Input
LASTNONBLANK
This method returns the last non blank value of the aggregated Dimension.
Source_blocknBY LASTNONBLANK: mapping attribute ]
Supported Data Types - All Types
Return Data Type - same as Input
LASTNONZERO
This method returns the last non zero value of the aggregated Dimension.
Source_blockpBY LASTNONZERO: mapping attribute ]
Supported Data Types - Number, Integer
Return Data Type - same as Input
LAST
This method returns the last value of the aggregated Dimension.
Source_blockcBY LASTBLANK: mapping attribute ]
Supported Data Types - All Types
Return Data Type - same as Input
ANY
Returns TRUE if at least one aggregated item is TRUE, else FALSE.
Source_blockaBY ANY: mapping attribute ]
Supported Data Types - Boolean
Return Data Type - same as Input
ALL
Returns TRUE if all aggregated items are TRUE or BLANK, else FALSE.
If all aggregated items are BLANK, then the BY ALL result will also be BLANK. Because Pigment’s engine is sparse, blank values are not stored in the database.
Source_blockmBY ALL: mapping attribute ]
Supported Data Types - Boolean
Return Data Type - same as Input
COUNT
Returns the number of aggregated items (BLANK cells are not included).
Source_blocknBY COUNT: mapping attribute ]
Supported Data Types - All types
Return Data Type - Integer
COUNTBLANK
Returns the number of BLANK items in the aggregated dimension.
Source_blockcBY COUNTBLANK: mapping attribute ]
Supported Data Types - All types
Return Data Type - Integer
COUNTALL
Returns the number of aggregated items (BLANK cells are included)
Source_blockoBY COUNTALL: mapping attribute ]
Supported Data Types - All types
Return Data Type - Integer
COUNTUNIQUE
Returns the number of unique values in the aggregated dimension (BLANKS not included)
Source_blocklBY COUNTUNIQUE: mapping attribute ]
Supported Data Types - All types
Return Data Type - Integer
TEXTLIST
Returns the list of aggregated text values, separated by a comma.
Source_block-BY TEXTLIST: mapping attribute ]
Supported Data Types - Text
Return Data Type - same as Input
Excel equivalent: VLOOKUP or SUMIF
See also: REMOVE