



The goal of this article is to describe what options are available when configuring imports and how it impacts how your data will be refreshed.
When you create a Transaction List, most of the time you’ll want to refresh/update this data. If that’s the case, you will likely want to consider some of the following questions:
-
Am I adding new data each time I load a new file to this Transaction List?
-
Am I always adding:
-
the last X days of data (last 30 days or last 90 days for example)?
-
the current month of data (or previous month)?
-
-
What will be the frequency
-
Once a month?
-
Several times a month?
-
-
Am I going to need to do late adjustments?
Depending on your answers, you’ll be able to configure your Transaction List imports to fit your needs. Let’s deep dive into the options you have, how you can use them and what they do.
The basics
You load a file (or you run a connector, but in the end Pigment receives a file ) and choose to map N properties in a standard way.
What happens ?
Each time you do a new load, new lines are added. If you load the same line twice, you will have duplicate data. To avoid duplicating data, you can either use a unique identifier or scope your import - we’ll see both methods in this article
PS: new lines are always added at the end of a TL. If you don’t have any specific ordering setup and you’re looking for the lines you just added, scroll to the end of your Transaction List :)
PS 2: You can now automatically add a Load Timestamp during step 1 of your mapping. It can be super helpful later on to better understand when data has been loaded.

Using Scoped Dimension options
Now let’s say that you’re doing several imports a month, and you’re loading the total of sales by product by month. We are in January. You’ve loaded a first file on 4th of Jan containing your sales data. The file you will load on the 20th of Jan will have the same lines per product for the month of January 22, but the total sales will be different as 16 days have gone by.
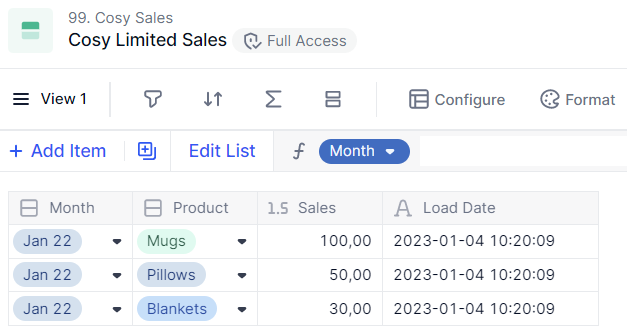
In this case, what you want to do is replace the data you previously loaded with the data you are about to load..
To do so, you can use the Scoped Dimension options in “advanced options” in the Step 2 of the mapping screen.
Here, you can select a dimension that exists in your transaction list properties, for example month.
Once it’s selected, here’s what happens:
-
Pigment receives your new file, knows that your import is scoped on the property “Month”, will detect which items of Month exist in your file (January 22 in our case).
-
Once Pigment knows that, all existing items in the current transaction List that have “Jan 22” as a Month property will be automatically deleted.
-
Then, lines from the files will be added.
This enables you to always keep the latest up-to-date data for a given scope (here, Month). You can select multiple properties. You can also select “Entire List” which will simply delete all existing items and replace them with the new ones
If I load a new file where I have 250 sales for Mugs, 100 for Pillows and 150 for Blankets, the first important thing to understand is the Import summary :
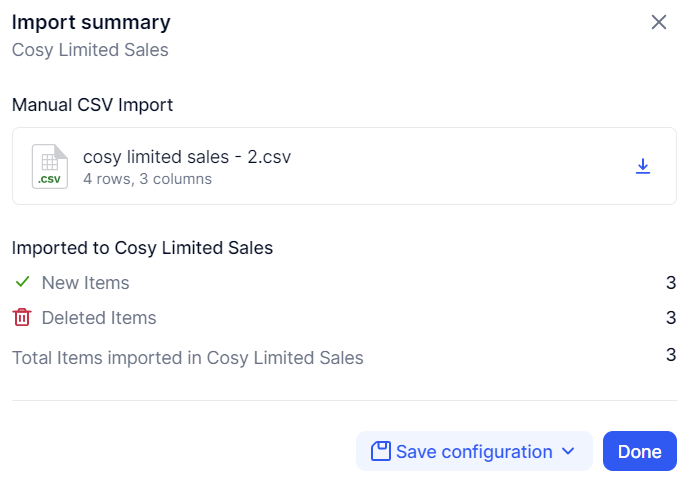
It indicates clearly that my pre-existing 3 lines have been deleted because they were all for January 22. 3 new lines were added, coming from my new file.
The transaction list now looks like this:
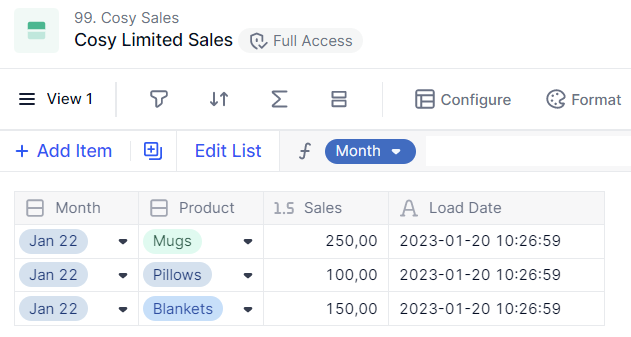
Sales are up-to-date and the load date shows when this line has been updated.
This option is great when loading, at a frequent pace, the last or current month of data. This way, you’ll always have the latest data for this month.
If I load data with a specific scope defined, this file replaces all existing data in that scope.
Using a unique ID for each line of my import
Now let’s imagine that you know you are loading again the same lines with values that might be updated. In your source system you have a row of data that has changed and you want this change to be represented in Pigment. With the current setup, you would have to delete the existing item in the Transaction List and then load your new file. This is not scalable of course.
In this case, you can use a property in your Transaction List, and set it as unique. Pigment will use it to recognize that this line already exists, and that we want to update this line, not add a new one.
Of course, you need to have a unique property at your disposal to do so. If the option to add a unique ID in your source system is not obvious, contact their support services.
Here’s another example where we have a Transaction List with Opportunities data. As you can see, the first property header Opportunity ID is underlined, meaning it’s unique.
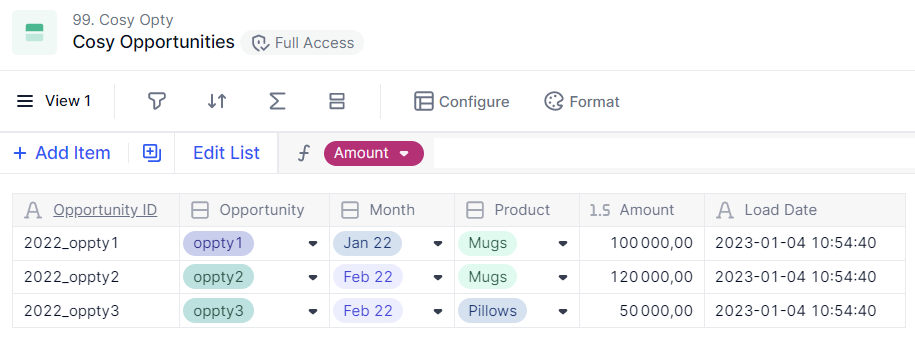
You can verify that by checking its setting:
We can now load a new file containing 4 opportunities:
-
The 3 opportunities we already have but where the amount for oppty1 has changed from 100 000 to 200 000
-
One new opportunity
First, let’s have a look at the import summary.
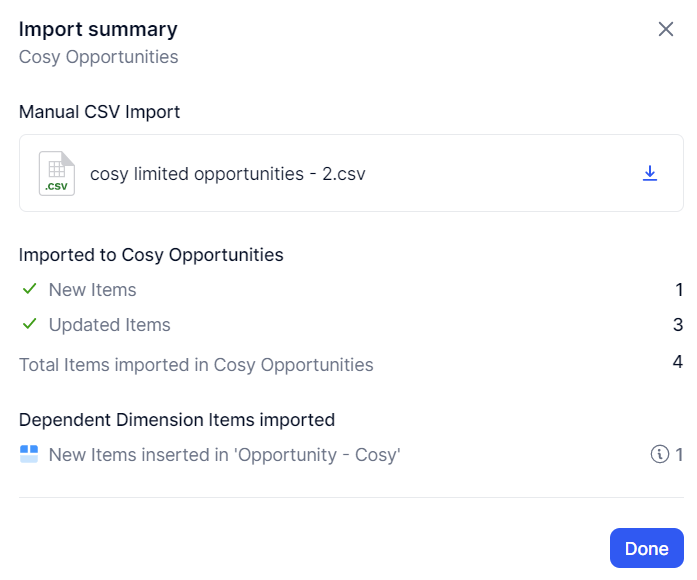
We understand that a new opportunity Item has been added (our new opportunity), and that 3 other items were updated (our 3 existing items).
The Transaction List now looks like this:
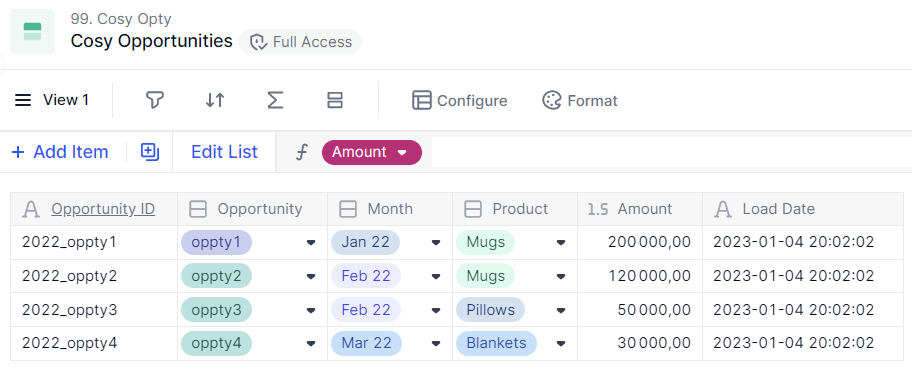
Please note that in this case, all 3 existing opportunities have been updated because we are using the Load Date pigment property. If we do not, oppty2 and oppty3 would have not been amended.
This option is great if you are loading the same data again and again as it will ensure you have the latest status at your disposal. You know that part of this data can change over time, but you don’t necessarily know when and you want to capture this change.
If I load a line with a unique ID that already exists in my transaction list, it will update the properties, not load a new line. Lines with new unique IDs will be added.
Avoid unpleasant surprises
How your data is produced and structured will inform which of the above options you want to use. You’ll want to structure your imports accordingly and think in advance about how your data will be refreshed.
Do not use scoped dimension if your load does not cover an entire scope
Do not scope on month if your load does not always contain a full month of data. For example, do not use it if you’re loading data using a method like the last 30 days of data. If you do so, even by having only 1 day in the previous month, you’ll delete every other day of data that month.
Be careful if you’re loading “late” data, or doing late bookings
Using scoped dimensions, when updating a small amount from 6 months ago. If your adjustment does not contain the full month, you will replace your existing data with the only adjustments you made. The unique id setup might be relevant here : if you want to update a line that is already in the Transaction List, only that line will be impacted.