
When building applications, there are certain folders and structures we use in almost every use case application (read: not applicable to the Hub or specific Admin applications). Read this article to know more about general architecture on your workspace. This folder structure allows us to order the blocks intentionally, separate out the blocks that serve important functions, and maintain flexibility to add new blocks as the application scope and complexity evolves.
Pro tip: just like a nice cabernet sauvignon and an aged cheddar, this article pairs beautifully with our naming convention best practices.
Here is an example of a Revenue Planning application which uses our recommended structure:
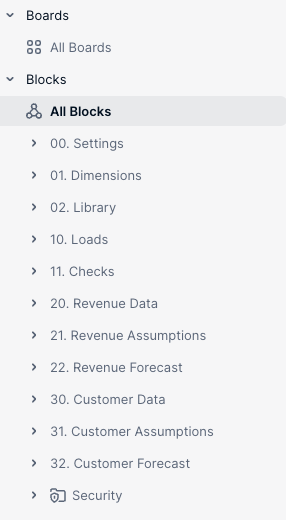
Basic folders
The 0X folders seen in the example are those that you will usually find in any use-case application, so let’s take a deep dive into each:
00. Settings: this folder is meant to contain all the blocks that are used for settings in the application – i.e. any blocks created to configure/tailor the application or for technical purposes – like mapping metrics or variables metrics like the “Load Month”.
01. Dimensions: this folder will be used to keep all the dimensions that are specific to this application. Having this dimension folder appearing at the top makes it convenient to quickly find all of your application-specific dimensions as you’re modeling.
02. Library: This is a folder we recommend creating to visualise the inflows and outflows metrics between our application and others in the workspace. It will usually contain both Push and Pull metrics, Push being sanitised versions of the end result metrics of our application which need to be shared with other applications, and Pull being the receiving blocks of other applications’ Push metrics. We like to name them with a prefix to indicate whether they are Push or Pull; for example: “Push_Name of the metric” or “Pull_Name of the metric.” Click here to read our article about why you should use Library folders.
03. Assumptions: This is a dedicated folder for model assumptions that can be used when relevant, such as “Yearly Tax Rates (by Country)”, “Yearly Increase”, and “Month of Increase”. If a model requires more than a few assumptions, it can be clearer to keep them with the “themed” folder that will be used after (see below), but if you have a model with fewer assumptions, an assumptions-specific folder can help keep these to hand.
Data folders
In the 1X range, we usually create folders for data loads and checks to help consolidate and validate the data being used in your application.
10. Data Loads: all the transaction lists containing data coming from external sources can be stored in this folder as well as the metrics that we use to aggregate data from those transaction lists (we call them staging metrics).
11. Data Checks: metrics that are used to check the quality of the data or to fill missing mapping, run numbers checks and that might be displayed on board.
Themed Folders
In the 2X range and beyond, we will then have themed folders based on the calculation step of the model. For example, in a Revenue Planning application, we want to start by calculating the Pipeline Forecast and then compare it to the Sales Capacity Forecast. Our folder structure will look like this:
20. Pipeline Data: metrics aggregating relevant data from the transaction list in 10. Data Load
21. Pipeline Assumptions: metrics used to input or calculate assumptions used for the forecast calculation
22. Pipeline Forecast: forecast results metrics
We could apply the same structure on the following folders:
30. Sales Capacity Data
31. Sales Capacity Assumptions
32. Sales Capacity Forecast
Alternatively, you might want to keep any transaction lists (previously mentioned in the 1X range) with the associated folders with an organisation like this one:
20. Pipeline Load
21. Pipeline Data
22. Pipeline Assumptions
23. Pipeline Forecast
Or even like this, with the transaction list and the data metrics together in one folder:
30. Sales Capacity Load & Data
31. Sales Capacity Assumptions
32. Sales Capacity Forecast
As expected there are many ways to handle and arrange the basic folders in an application. There is no “right” way to do it, but if it’s relevant to your use case, try to get as close as possible of what has been presented in this article or like in the example below:
| Workforce application | Opex application |
|---|---|
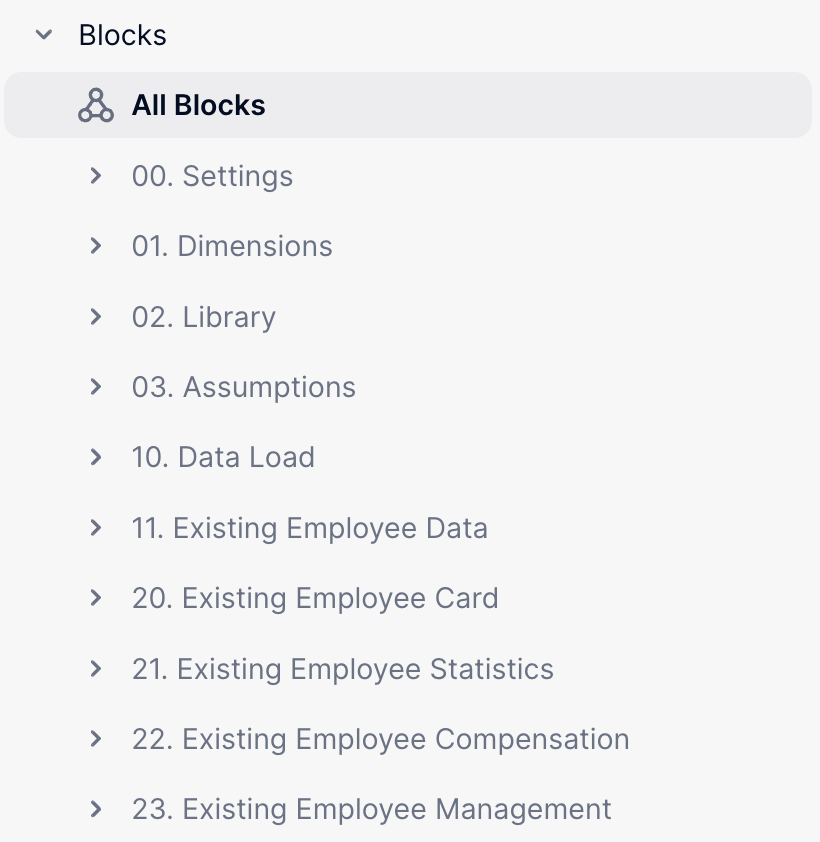 | 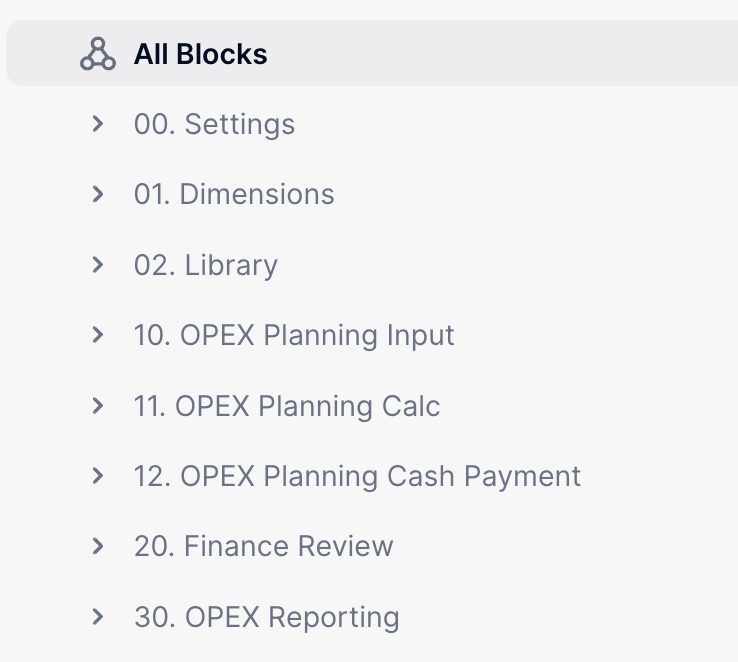 |
By structuring folders in this way, we can make sure that all our frequently referenced blocks are easily visible at the top (the 0X folders), and the rest of our blocks are organised thematically in an easy-to-navigate way. Don’t forget to read all about our approach to naming conventions to better understand why we name our folders this way, and how we name the blocks themselves, as well as other objects in your workspace.